Contact:
Saif M. Mohammad (saif.mohammad@nrc-cnrc.gc.ca)
Papers
The Natural Selection of Words: Finding the Features of Fitness. Peter D. Turney and Saif M. Mohammad. PLoS One, 14 (1):e0211512. January 2019.
Paper
(pdf) BibTeX Code and Data
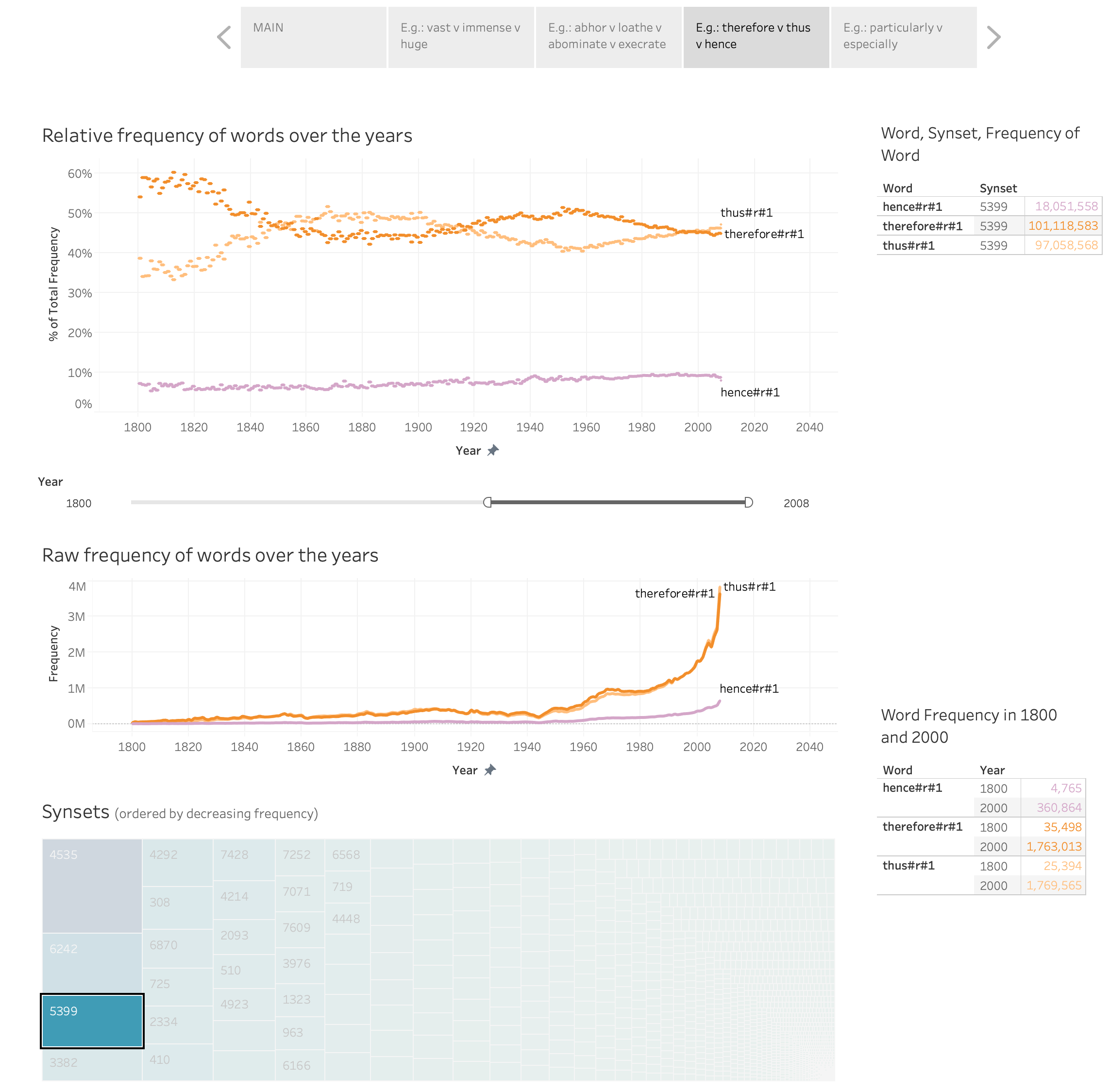
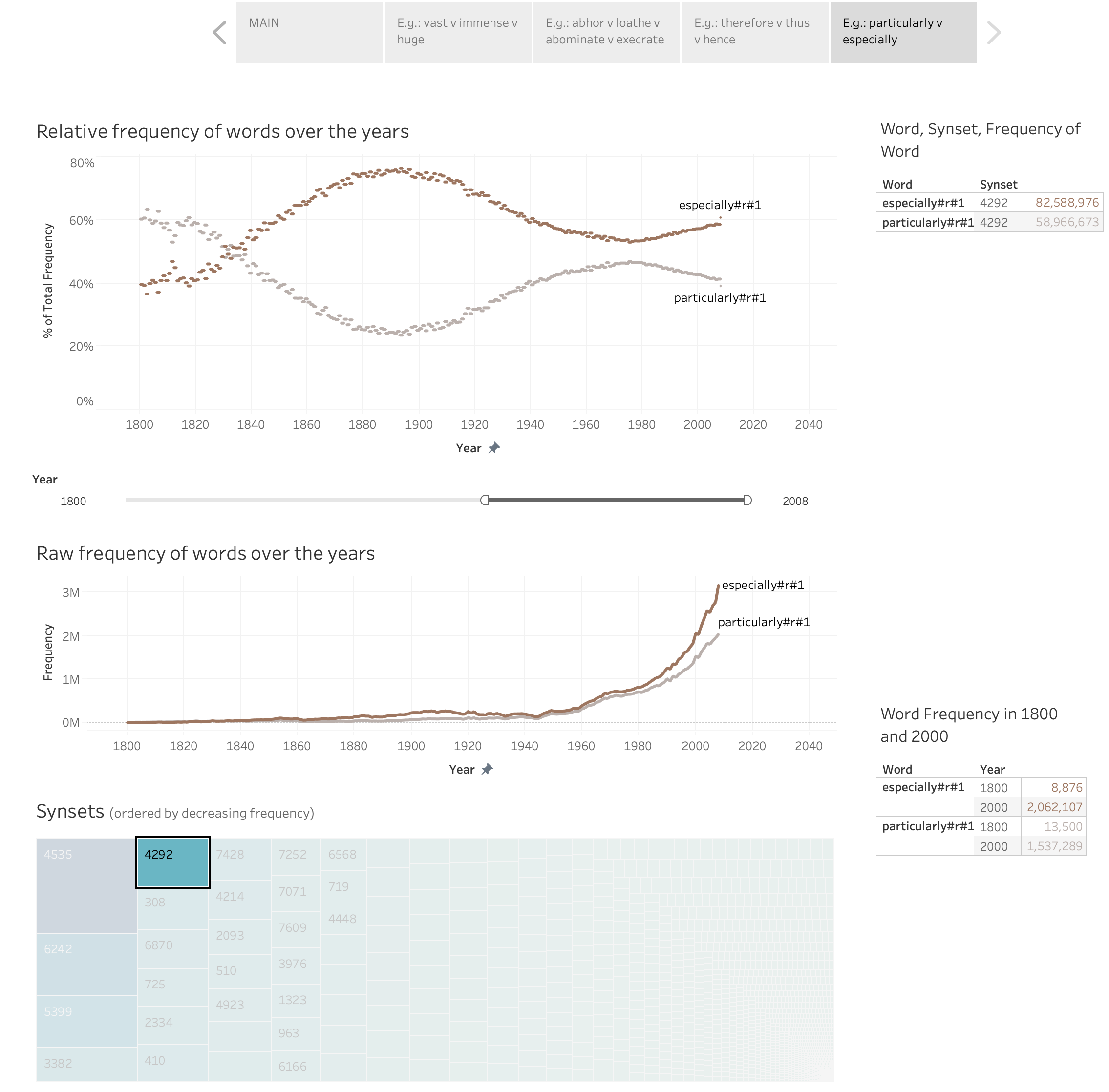
We introduce a dataset for studying the evolution of words, constructed from WordNet and the Google Books Ngram Corpus. The dataset tracks the evolution of 4,000 synonym sets (synsets), containing 9,000 English words, from 1800 AD to 2000 AD. We present a supervised learning algorithm that is able to predict the future leader of a synset: the word in the synset that will have the highest frequency. The algorithm uses features based on a word’s length, the characters in the word, and the historical frequencies of the word. It can predict change of leadership (including the identity of the new leader) fifty years in the future, with an F-score considerably above random guessing. Analysis of the learned models provides insight into the causes of change in the leader of a synset. The algorithm confirms observations linguists have made, such as the trend to replace the -ise suffix with -ize, the rivalry between the -ity and -ness suffixes, and the struggle between economy (shorter words are easier to remember and to write) and clarity (longer words are more distinctive and less likely to be confused with one another). The results indicate that integration of the Google Books Ngram Corpus with WordNet has significant potential for improving our understanding of how language evolves.
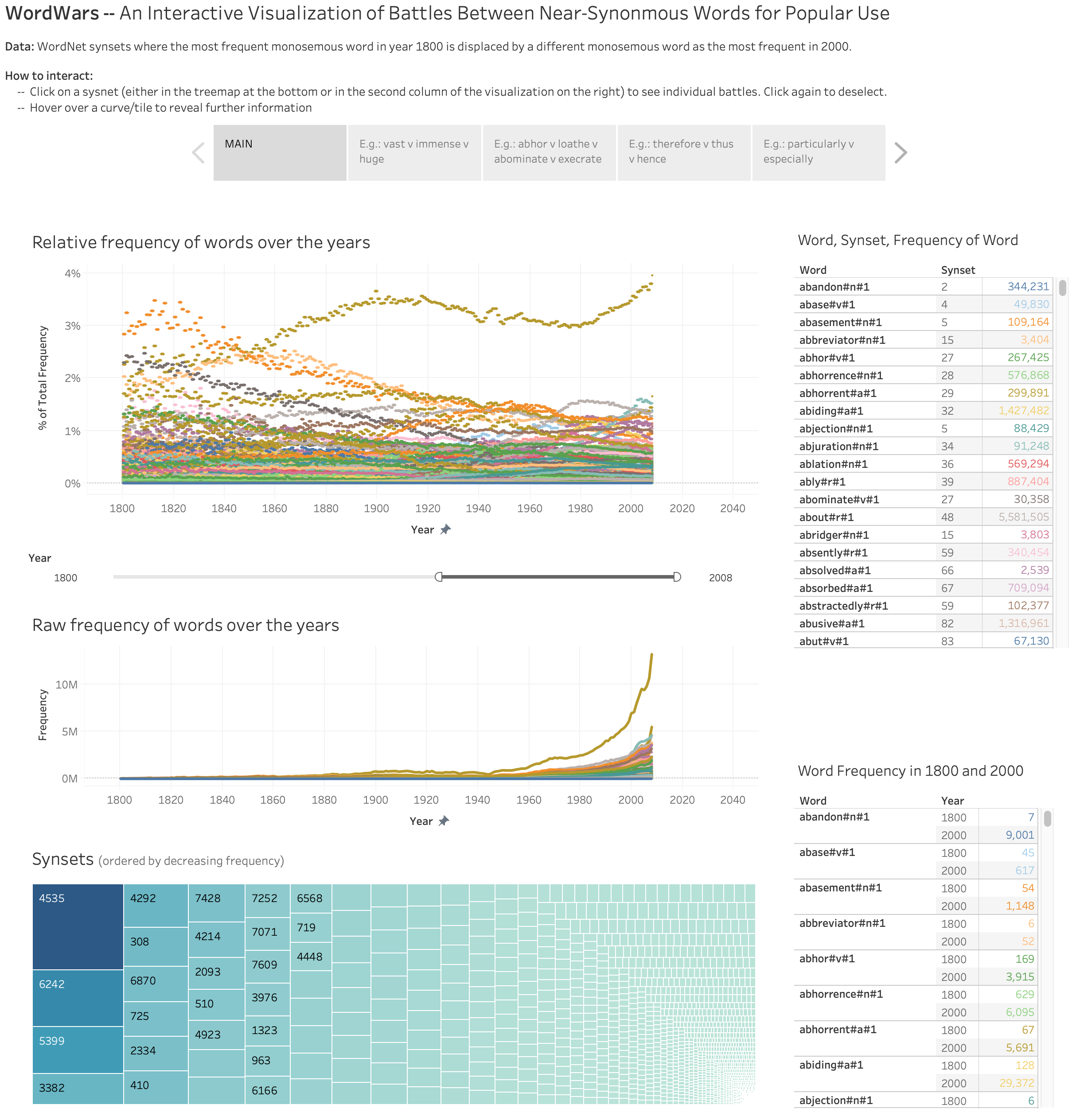
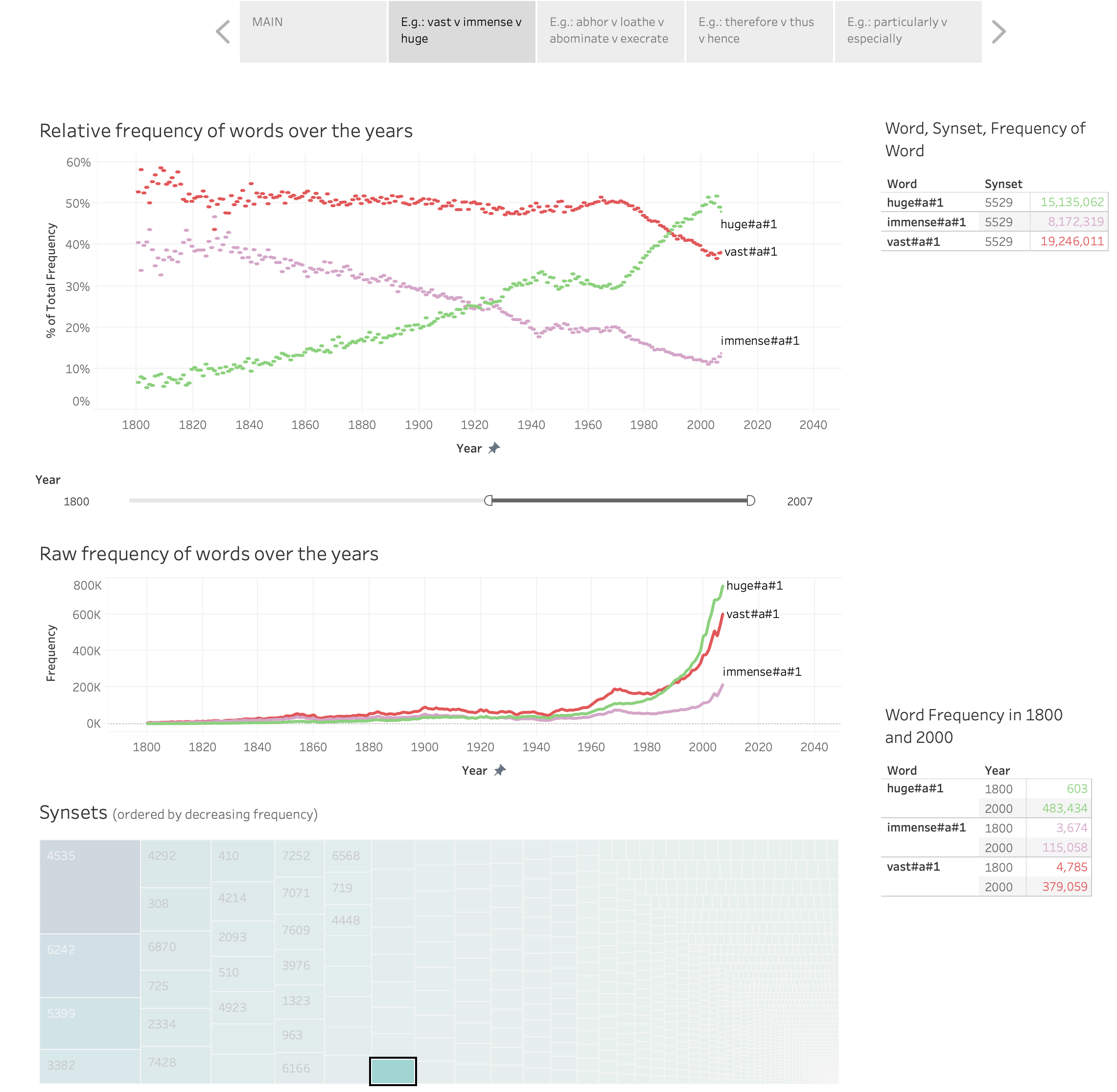
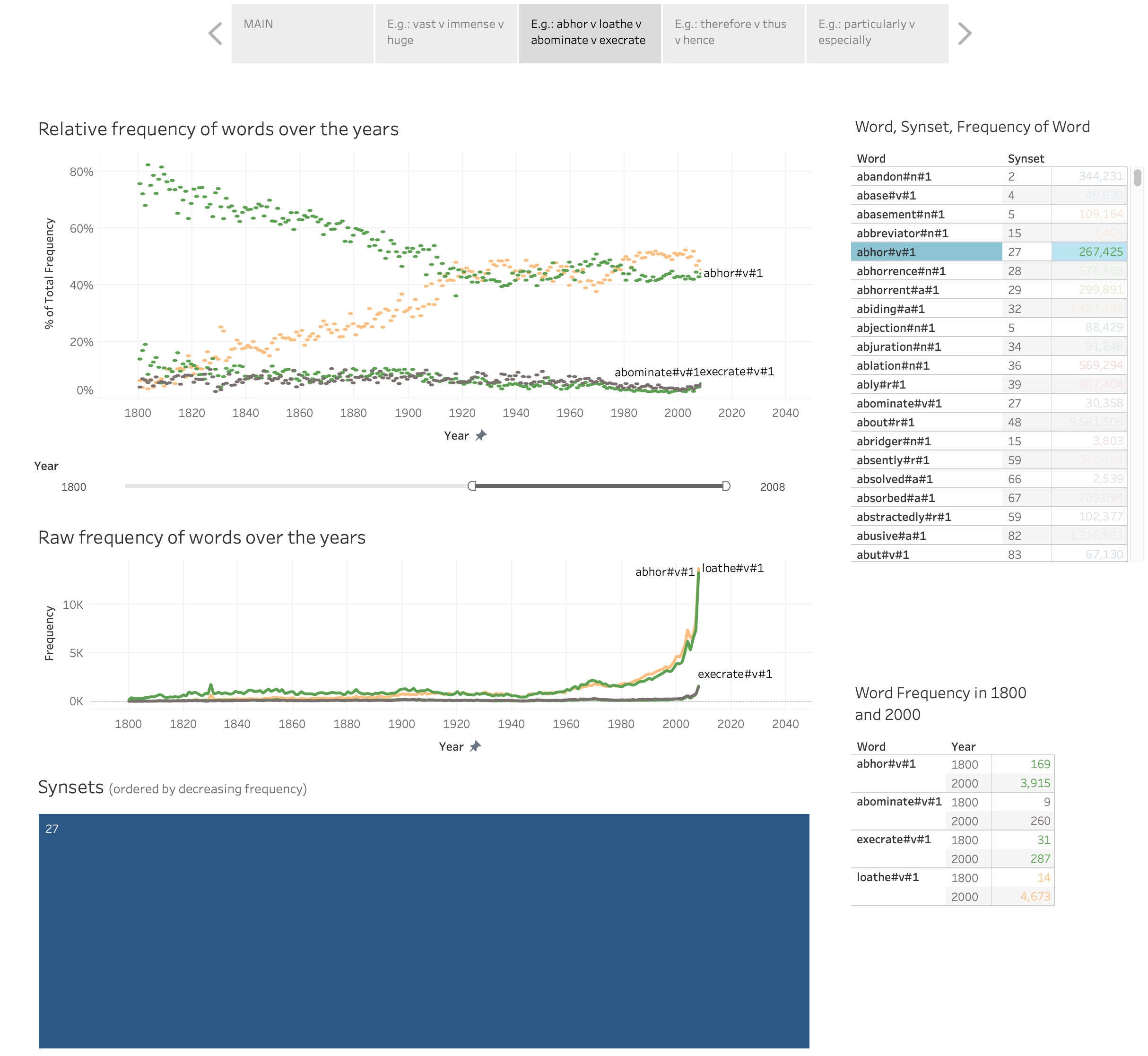
WordWars: A Dataset to Examine the Natural Selection of Words. Saif M. Mohammad. In Proceedings of the 12th Language Resources and Evaluation Conference (LREC-2020), Marseille, France.
Paper (pdf) BibTeX Poster Data
There is a growing body of work on how word meaning changes over time: mutation. In contrast, there is very little work on how different words compete to represent the same meaning, and how the degree of success of words in that competition changes over time: natural selection. We present a new dataset, WordWars, with historical frequency data from the early 1800s to the early 2000s for monosemous English words in over 5000 synsets. We explore three broad questions with the dataset: (1) what is the degree to which predominant words in these synsets have changed, (2) how do prominent word features such as frequency, length, and concreteness impact natural selection, and (3) what are the differences between the predominant words of the 2000s and the predominant words of early 1800s. We show that close to one third of the synsets undergo a change in the predominant word in this time period. Manual annotation of these pairs shows that about 15% of these are orthographic variations, 25% involve affix changes, and 60% have completely different roots. We find that frequency, length, and concreteness all impact natural selection, albeit in different ways.
Keywords: Natural selection, lexical semantics, words, evolution, word length, frequency, concreteness
|