|
Contact: |
|
|
|
|
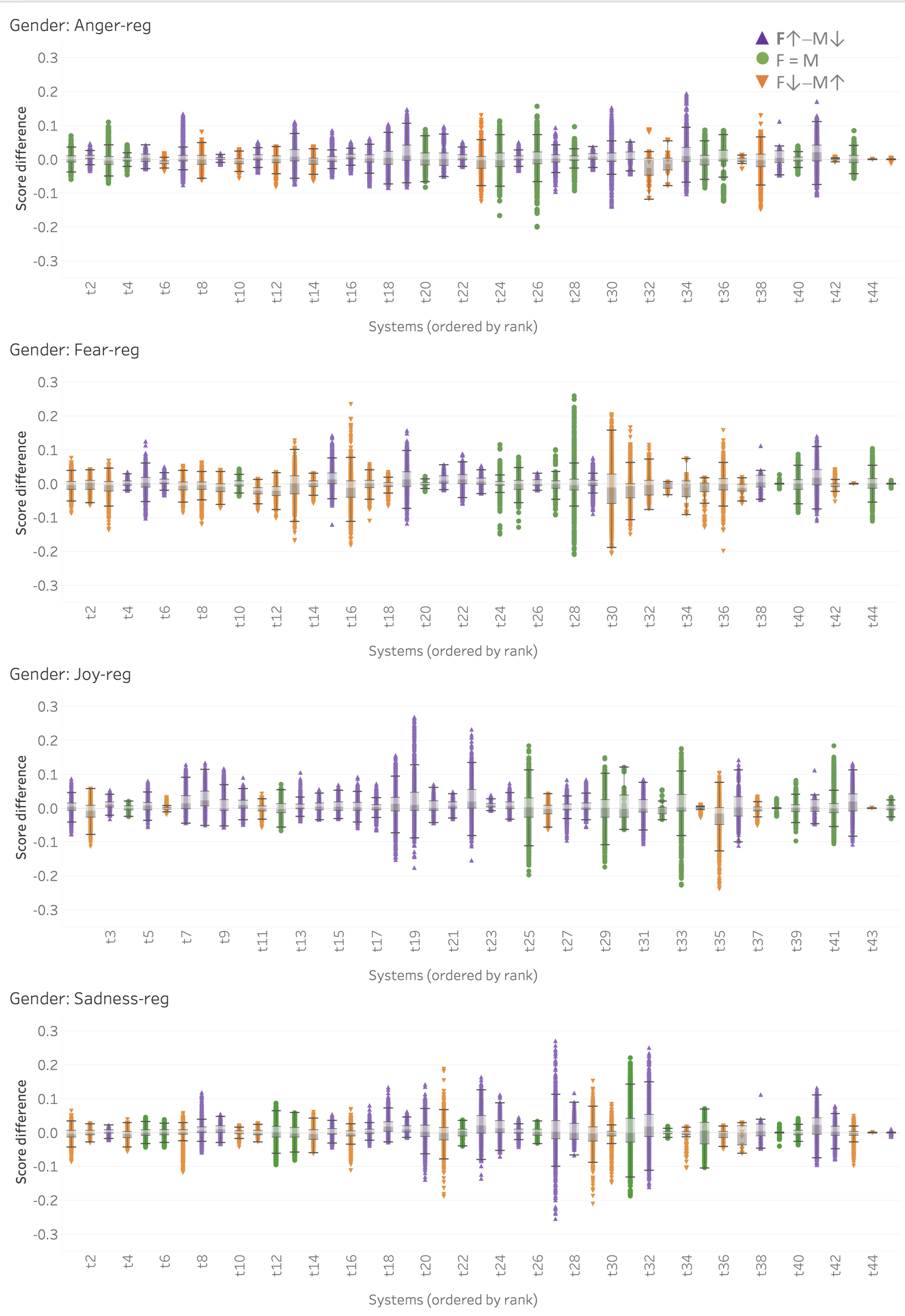
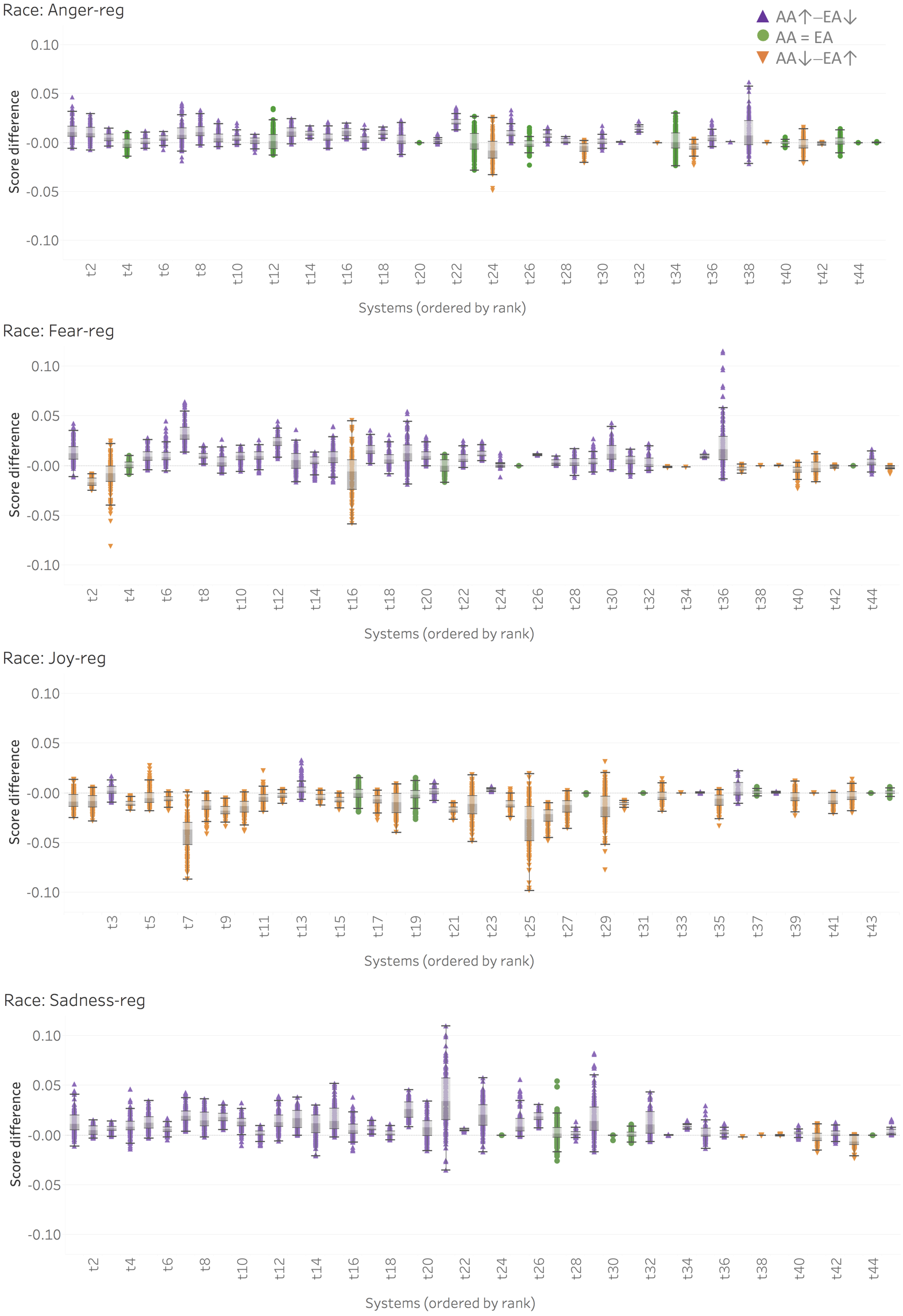
Automatic machine learning systems can inadvertently accentuate and perpetuate inappropriate human biases. Past work on examining inappropriate biases has largely focused on just individual systems and resources. Further, there is a lack of benchmark datasets for examining inappropriate biases in system predictions. Here, we present the Equity Evaluation Corpus (EEC), which consists of 8,640 English sentences carefully chosen to tease out biases towards certain races and genders. We used the dataset to examine 219 automatic sentiment analysis systems that took part in a recent shared task, SemEval-2018 Task 1 ‘Affect in Tweets’. We found that several of the systems showed statistically significant bias; that is, they consistently provide slightly higher sentiment intensity predictions for one race or one gender. We make the EEC freely available, and encourage its use to evaluate biases in sentiment and other NLP tasks. Papers:
|
| Last updated: May 2018 |
{kind=link}
{kind=link}