Details about this dataset and experiments on automatic classification for stance and sentiment are available in these papers:
Stance and Sentiment in Tweets. Saif M. Mohammad, Parinaz Sobhani, and Svetlana Kiritchenko. Special Section of the ACM Transactions on Internet Technology on Argumentation in Social Media, 2017, 17(3). Paper (pdf)BibTeX
Detecting Stance in Tweets And Analyzing its Interaction with Sentiment. Parinaz Sobhani, Saif M. Mohammad, and Svetlana Kiritchenko. In Proceedings of the Joint Conference on Lexical and Computational Semantics (*Sem), August 2016, Berlin, Germany. Paper
(pdf)BibTeX
This study has been approved by the NRC Research Ethics Board (NRC-REB) under protocol number 2015-08. REB review seeks to ensure that research projects involving humans as participants meet Canadian standards of ethics.
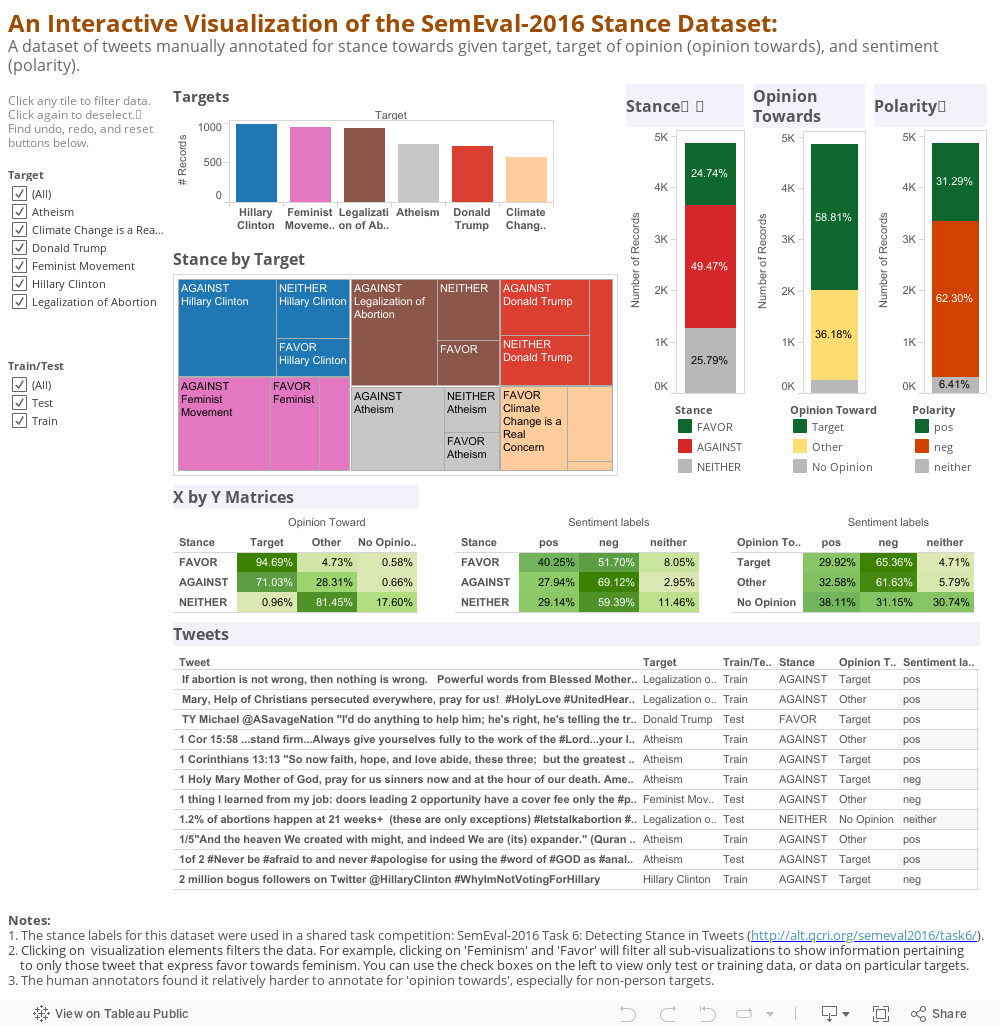
The stance labels for this dataset were used in a shared task competition: SemEval-2016 Task 6: Detecting Stance in Tweets. Further details about the data and the stance detection task can be found at the task website. The SemEval data is available for download here.
Semeval-2016 Task 6: Detecting Stance in Tweets. Saif M. Mohammad, Svetlana Kiritchenko, Parinaz Sobhani, Xiaodan Zhu, and Colin Cherry. In Proceedings of the International Workshop on Semantic Evaluation (SemEval ’16). June 2016. San Diego, California. Paper (pdf)BibTeXTask Website
Automatic Stance Detection System: Many of the same features used in the NRC-Canada sentiment system were also used in a stance-detection system that outperformed submissions from all 19 teams that participated in SemEval-2016 Task 6 (Mohammad et al., 2017). Our stance system is not publicly available yet. However, the AffectiveTweets Package can be used to generate feature vectors from a large number of affect lexicons similar to those used by us for stance and sentiment.
Designated Contact Person:
Dr. Saif M. Mohammad Senior Research Officer at NRC (and one of the creators of the resource on this page)
saif.mohammad@nrc-cnrc.gc.ca
Terms of Use:
All rights for the resource(s) listed on this page are held by National Research Council Canada.
The resources listed here are available free for research purposes. If you make use of them, cite the paper(s) associated with the resource in your research papers and articles.
If interested in commercial use of any of these resources, send email to the designated contact person. A nominal one-time licensing fee may apply.
If referenced in news articles and online posts, then cite the resource appropriately. For example: "This application/product/tool makes use of the <resource name>, created by <author(s)> at the National Research Council Canada." If possible, hyperlink the resource name to this page.
If you use the resource in a product or application, then acknowledge this in the 'About' page and other relevant documentation of the application by stating the name of the resource, the authors, and NRC. For example: "This application/product/tool makes use of the <resource name>, created by <author(s)> at the National Research Council Canada." If possible, hyperlink the resource name to this page.
Do not redistribute the resource/data. Direct interested parties to this page. They can also email the designated contact person.
If you create a derivative resource from one of the resources listed on this page:
Please ask users to cite the source data paper (in addition to your paper).
Do not distribute the source data. See #6 above.
Examples of derivative resources include: translations into other languages, added annotations to the text instances, aggregations of multiple datasets, etc.
If you are interested in uploading our resource on a third-party website or to include the resource in any collection/aggregate of datasets, then:
Email the designated contact person to begin the process to obtain permission.
After obtaining permission, any curator of datasets that includes a resource listed here must take steps to ensure that users of the aggregate dataset still cite the papers associated with the individual datasets. This includes at minimum: stating this clearly in the README and providing the citing information of the source dataset.
By default, no one other than the creators of the resource have permission to upload the resource on a third-party website or to include the resource in any collection/aggregate of datasets.
National Research Council Canada (NRC) disclaims any responsibility for the use of the resource(s) listed on this page and does not provide technical support. However, the contact listed above will be happy to respond to queries and clarifications.
If you send us an email, we will be thrilled to know about how you have used the resource.